PoseAug: A Differentiable Pose Augmentation Framework for 3D Human Pose Estimation (CVPR21’, NUS)
[0] Summary
(remark)
- Best Paper Candidates in CVPR21’
- SOTA in Weakly Supervised Human3.6M
-
Showed significant&consistent performance boost in weakly-supervised setting
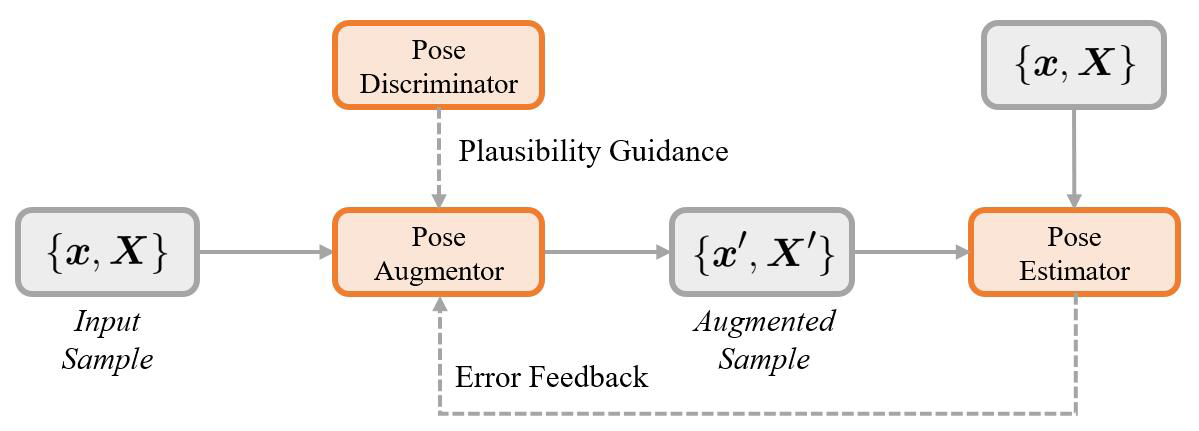
(methodology)
- Proposed learnable data augmentation on 3D Human Pose task
- Trained pose augmentor from the error of pose estimator
- Help it generate diverse and realistic augmentation
- Introduced part-aware 3D discriminator
[1] Intro - Problem Def.
(Prob.)
- Existing 3D human pose estimators → poor generalization performance to new datasets
- Why? → Limited diversity of 2D-3D pose pairs
- Previous augmentation → offline manner + no consideration on model training
- Prone to generate too easy augmentation for model
- Used pre-defined rules which limits diversity
(Sol.)
- We should increase the diversity of augmentation!
- Utilizing the estimation error of pose estimator in an online manner
- To generate more diverse and harder poses
- By using differentiable augmentations (e.g. adjust posture, bodysize, view point, position)
- Not by deterministic augmentations which are not learnable (= couldn’t be improved through training)
- With part-aware discriminator
- Not with the previous original discriminator considering whole body
- Utilizing the estimation error of pose estimator in an online manner
[2] Method
(Preliminaries)
-
Conventional Pose Estimator Training
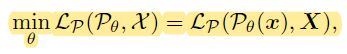
- $\chi = {x,X}$ := 2D-3D pose pair
- $P_\theta$ := Pose Estimator ($\theta$ : parameter)
- $L_P=\Vert\textbf{X}-\tilde{\textbf{X}}\Vert_2^2$ ($\tilde{\textbf{X}}$ : predicted pose)
-
PoseAug Training
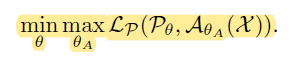
- $A_{\theta_A}$ := Pose Augmentor ($\theta_A$ : parameter)
- Objective: To increase the loss
- Pose Discriminator is needed to prevent it from generating implausible poses
- Objective: To increase the loss
- $A_{\theta_A}$ := Pose Augmentor ($\theta_A$ : parameter)
- Structure : 3 parts
- Pose Augmentor
- Pose Discriminator
- Pose Estimator
→ They interact with each others
- End-to-End training strategy
- Update each part alternatively
- Firstly train the pose estimator for stable training
(1) Pose Augmentor
(Process)
- (1st step) given 3D pose $\textbf{X} \in \mathbb{R}^{3 \times J} \ \rightarrow$ bone vector $\textbf{B} \in \mathbb{R}^{3 \times (J-1)}$
-
i.e. $\textbf{B}=H(\textbf{X})$
A bone $b_k=p_r-p_t=\textbf{X}c$
where, $p_r,\ p_t$ are joints
$c=(0,…,0,1,0,…0,-1,0,…0)^T$
And, $\textbf{B}=(b_1,b_2,…,b_{j-1})=\textbf{XC}$
Here, $\textbf{B}=\Vert\textbf{B}\Vert\times\hat{\textbf{B}}$
- $\hat{\textbf{B}} \in \mathbb{R}^{3 \times (J-1)}$ ; Bone Direction vector ~ Joint Angle
- $\Vert\textbf{B}\Vert \in \mathbb{B}^{1 \times (J-1)}$ ; Bone Length vector ~ Body Size
-
- (2nd step) Apply MLP to $\textbf{X}$ for feature extraction
- Gaussian Noise is concatenated to $\textbf{X}$ for further randomness
- (3rd step) Regress augmentation parameters $\gamma_{ba},\ \gamma_{bl},\ (R,t)$ from extracted feature
- $\gamma_{ba} \in \mathbb{R}^{3\times(J-1)}$ ~ joint angles
- $\hat{\textbf{B}^{\prime}}=\hat{\textbf{B}}+\gamma_{ba}$
- $\gamma_{bl}\in\mathbb{R}^{1\times(J-1)}$ ~ body size
- $\Vert\textbf{B}^{\prime}\Vert=\Vert{\textbf{B}}\Vert\times(1+\gamma_{bl})$
- $(R,t)\in(\mathbb{R}^{3\times 3},\mathbb{R}^{3\times 1})$ ~ view-point, position
- $\textbf{X}^{\prime}=R[H^{-1}(\textbf{B}^{\prime})]+t$
- $\textbf{B}^{\prime}=\Vert\textbf{B}^{\prime}\Vert\times\hat{\textbf{B}^{\prime}}$
- $\textbf{X}^{\prime}=R[H^{-1}(\textbf{B}^{\prime})]+t$
- $\gamma_{ba} \in \mathbb{R}^{3\times(J-1)}$ ~ joint angles
- (4th step) Reproject $\textbf{X}^{\prime}$ to 2D space
- $x^{\prime}=\Pi(\textbf{X}^{\prime})$
- Perspective projection via the camera parameters from the original data (*ref)
- $x^{\prime}=\Pi(\textbf{X}^{\prime})$
→ Finally, we get augmented 2D-3D pair ${x^{\prime}, \textbf{X}^{\prime}}$
(Loss)
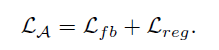
-
Feedback Loss $L_{fb}$
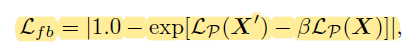
- Make the augmentation stay within proper range w.r.t. $L_P(\textbf{X})$
- $\beta\ (>1)$ controls the difficulty level
- Increase $\beta$ as training proceeds to generate more challenging data
-
Regularization Loss $L_{reg}$
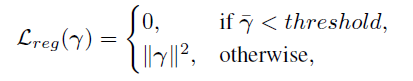
- Prevent extremely hard cases
- $\overline{\gamma}=mean(\gamma_{ba},\gamma_{bl})$
(2) Pose Discriminator
- Lack of priors may induce implausible augmentation (e.g. violating bio-mechanical structure)
- Used 2 types of discriminator
- $D_{3d}$ ~ Joint Angle
-
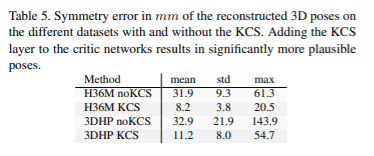
Further developed KCS, to part-aware KCS only focuses on local poses → More diverse poses can be generated!
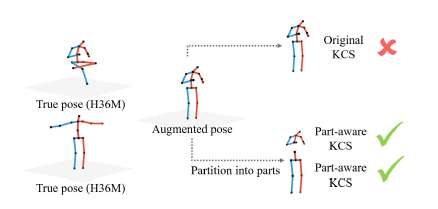
- KCS : A matrix representation of skeletal structural of human
-
KCS is quite critical for model to comprehend human body (e.g. physical symmetry)
*ref. (CVPR19’) RepNet
-
- local poses : torso, left/right arm/leg (total 5 parts)
- KCS : A matrix representation of skeletal structural of human
-
- $D_{2d}$ ~ Body Size, Viewpoint & Position
- $D_{3d}$ ~ Joint Angle
(Process)
($D_{3d}$)
- (1st step) Get $\hat{\textbf{B}}$ from $\textbf{X}$ and $\textbf{X}^{\prime}$
- (2nd step) Separate $\hat{\textbf{B}}$ into 5 parts (torso, left/right arm/leg)
- i.e. $\hat{\textbf{B}_i},\ (i=1,\dots,5)$
- (3rd step) Compute $KCS_{local}^i$ matrix
- $KCS_{local}^i=\hat{\textbf{B}_i}^T\hat{\textbf{B}_i}$
- Each entry of it is an inner product of two bone vectors
- Diagonal ~ Length of each bone
- Others ~ Angle of bone pair
- Each entry of it is an inner product of two bone vectors
- $KCS_{local}^i=\hat{\textbf{B}_i}^T\hat{\textbf{B}_i}$
- (4th step) Input $KCS_{local}^i$ to the $D_{3d}$
($D_{2d}$)
- Input 2D Pose to the $D_{2d}$
(Loss)
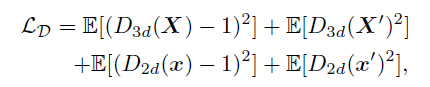
- Adopted LS-GAN loss (*ref) for both 3D and 2D spaces
(3) Pose Estimator
(Process)
- Estimate 3D poses from 2D poses
- (1st step) Feature Extraction from 2D Poses
- (2nd step) 3D Poses Regression
- Used various estimator in the experiment
(Loss)
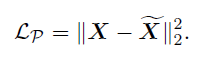
- Train the estimator with both original and augmented pose pairs jointly
- Very effective for the model to be robust
[3] Result
- 4 essential questions
- Q1. Is PoseAug able to improve performance of 3D pose estimator for both intra-dataset and cross-dataset?
- Q2. Is PoseAug effective at enhancing diversity of training data?
- Q3. Is PoseAug consistently effective for different pose estimators and cases with limited training data?
- Q4. How does each component of PoseAug take effect?
-
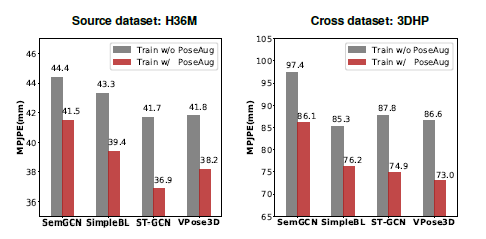
Q1. Is PoseAug able to improve performance of 3D pose estimator for both intra-dataset and cross-dataset?
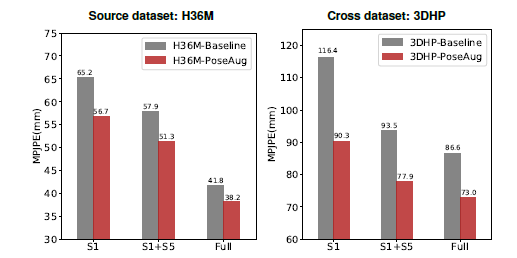
-
Q2. Is PoseAug effective at enhancing diversity of training data?
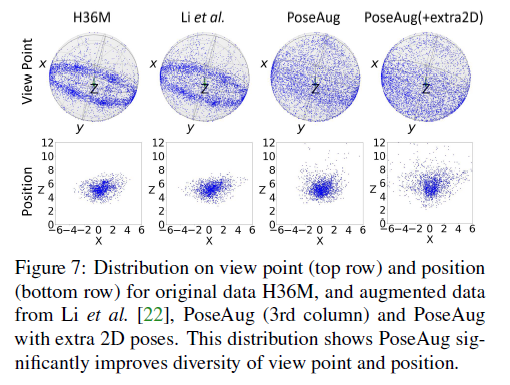
*Distribution of H36M is limited → The reason why the model trained on H36M hardly generalizable to in-the-wild
-
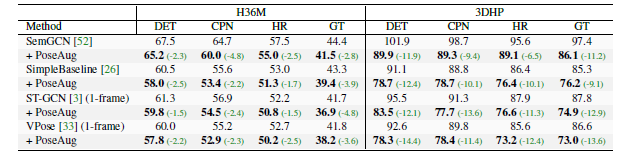
Q3. Is PoseAug consistently effective for different pose estimators and cases with limited training data?
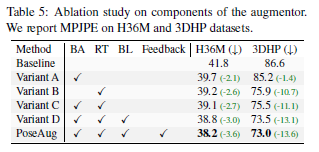
- Q4. How does each component of PoseAug take effect?
- Augmentation
- RT benefits the most
- Discriminator
-
$D_{3d}$ benefits better than $D_{2d}$
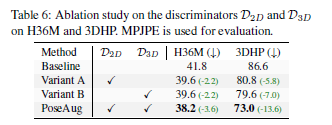
-
PA-KCS is clearly effective!
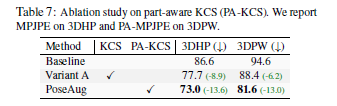
-
- Augmentation
[Reference]
To Discuss
Q1. How can we adopt this learnable augmenatation technique to Multi-Person Pose Estimation task?
Q2. How to adopt it in various domain (e.g. Video Classification) ?
Q3. Is there any additional component which will make further performance boost ?