CDML
19 August 2021
Collaborative Deep Metric Learning for Video Understanding (KDD 2018)
https://dl.acm.org/doi/pdf/10.1145/3219819.3219856
Motivation
- challenges in video understanding
- large video files, prohibited downlad and store
- computationally expensive
- costly labels
→ can be tackeld with metric learning
- goal
- learn embedding function → project video onto a low-dimensional space
- related videos: close to each other
- unrelated videos: far apart from each other
- embedding function should generalize well across different video understanding tasks
- learn embedding function → project video onto a low-dimensional space
Approach
- source of information
- raw video content
- extract image and audio features using SOTA deep neural networks
- user behavior - collaborative filtering information
- construct a graph - edge if co-watched by many users
- raw video content
- content-aware embedding: metric space of video content embedding trained to reconstruct the CF information
- mapping from video content to CF signals
- capture high-level semantic relationship between videos
- semi-supervised
Methodology
- Video Features
- extract visual / audio features using pre-trained models
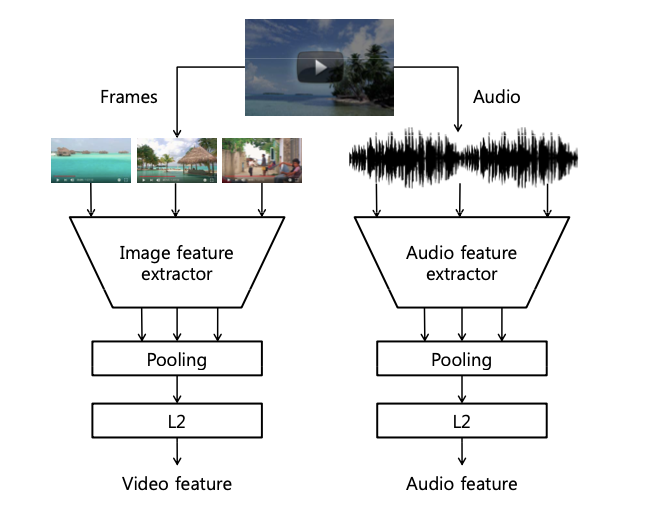
- video features
- 1 FPS using Inception-v3 trained on JFT dataset
- apply PCA to last hidden layer
- frame level features → video level : average pooling
- audio features
- VGG-inspired model
- non-overlapping 960 ms frames
- average pooled into video level
- Collaborative Deep Metric Learning
- construct a graph
- nodes: videos
- edges: co-watched, weight: co-watch frequency
- objective: co-watched videos → close in the embedding space
- ranking triplet loss: training data point - triplet of three videos
- anchor: more relevant to positive than negative
- positive
- negative
-
loss: hinge loss ← minimize
\[\mathcal{L}_{hinge}(f_\theta(x_i^a),f_\theta(x_i^p),f_\theta(x_i^n))= [||f_\theta(x_i^a)-f_\theta(x_i^p)||^2_2 - ||f_\theta(x_i^a)-f_\theta(x_i^n)||^2_2 + \alpha]_+\] - minimize the distance between anchor and positive, maximize the distance between anchor and negative
- $\alpha$: margin paramter, $=0$ in this experiment
- ranking triplet loss: training data point - triplet of three videos
-
extracted features → embedding network
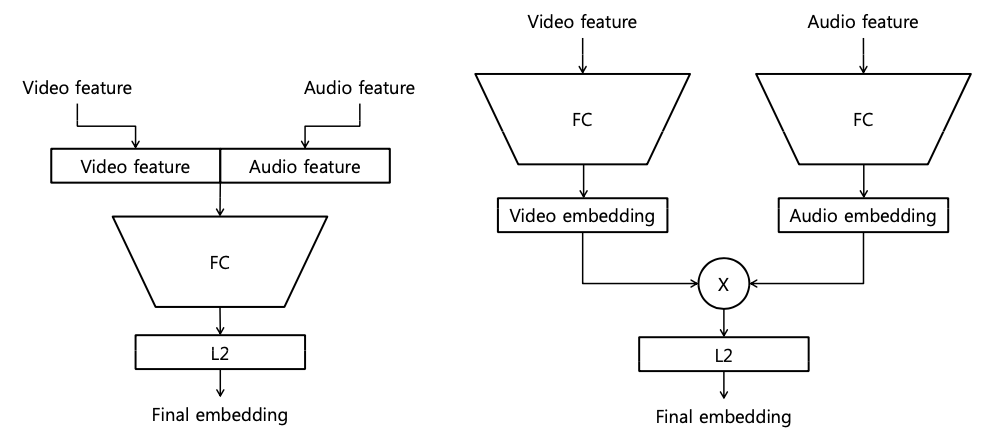
- early fusion
- concatenate input features → FC
- late fusion
- each input feature → FC layers → element-wise product
- early fusion
- construct a graph
Experiments
- semi-hard negative mining within mini-batch of 7200 triplets
- re-sample negative from the mini-batch
- negative not too far from the anchor
- closest one further from the positive
- re-sample negative from the mini-batch
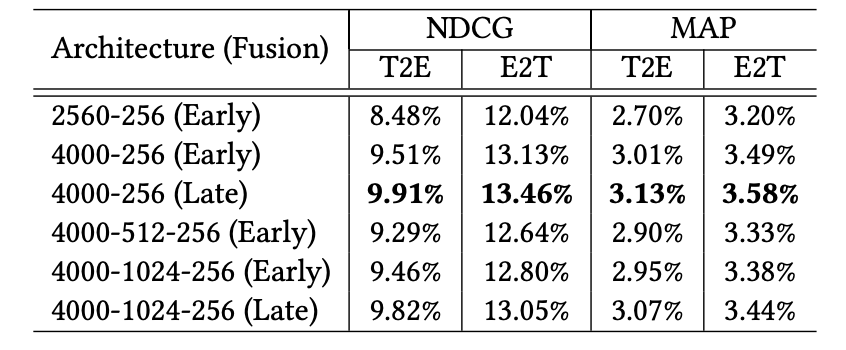
Task 1) Video Retrieval
- How?
- compute similarity score between two candidates (cosine similarity)
- query: video
- candidates: co-watched videos
- Dataset
- YouTube-8M dataset: 278M videos with 1000 or more views
- Evaluation
- NDCG
- MAP
-
Results
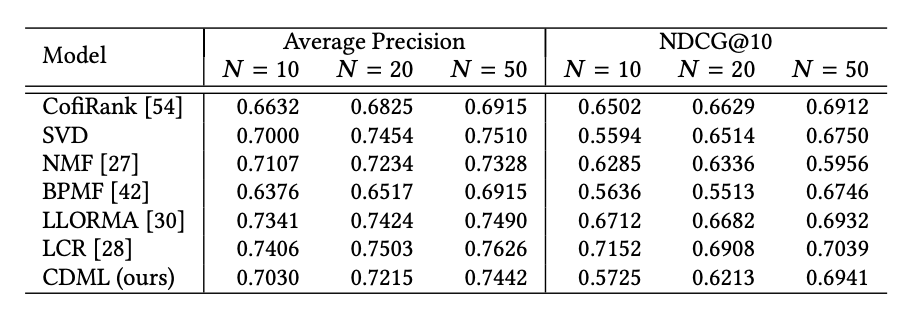
Task 2) Video Recommendation
- How?
- query: user - represented as recent watch history
- candidate video → compute similarity scores (cosine similarity) → recommend the video with highest arithmetic mean
- Dataset
- MovieLens 100K + YouTube trailers
- 25141 trailers for 26733 unique movies (94%)
- users less than 10 test rating excluded
- MovieLens 100K + YouTube trailers
- Evaluation
- NDCG@10
- MAP
-
Results
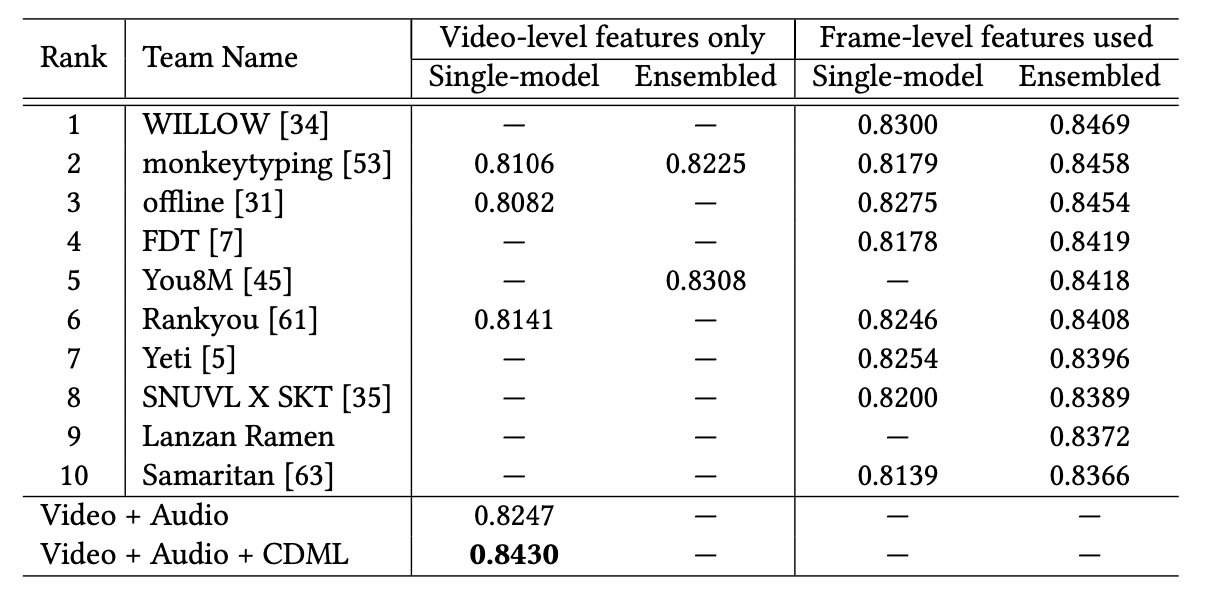
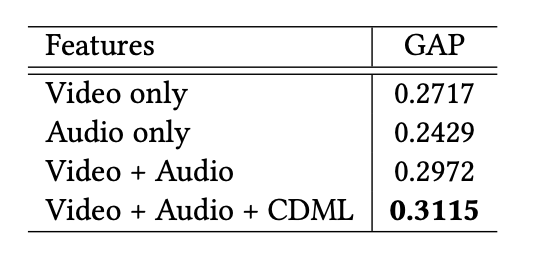
Task 3) Video Annotation / Classification
- How?
- multi-labeled classification problem
- feature vector of the video → binary vector * number of classes
- Dataset
- YouTube-8M (large-scale video classification challenge)
- MovieLens-20M (movie trailer → movie tag classification)
- Evaluation
- GAP (Global Average Precision): average precision based on the top 20 predictions per example
- MAP
-
Results
References
- https://dl.acm.org/doi/pdf/10.1145/3219819.3219856
- 이준석 교수님 MLVU 강의노트